Thiết kế cơ sở dữ liệu (database) luôn là một trong những công việc đầy khó khăn trong một bài toán xây dựng giải pháp phần mềm. Lựa chọn mô hình cơ sở dữ liệu (database model, viết ngắn gọn là data model) phù hợp, xây dựng các thực thể & mối quan hệ giữa chúng, thiết kế mô hình kiến trúc để đảm bảo database hoạt động ổn định, có khả năng mở rộng (scale) được khi có yêu cầu và đặc biệt đảm bảo tính chính xác, nhất quán của dữ liệu khi thực hiện sao chép ở phạm vi rộng. Đó là một vài trong rất nhiều các gạch đầu dòng cần phải làm cho các kỹ sư phần mềm khi “đụng” tới database.
Trong bài viết ngày hôm nay, mình sẽ cùng các bạn tìm hiểu về một giải pháp mới & khá thú vị của nền tảng điện toán đám mây Microsoft Azure có tên Azure Cosmos DB, một dịch vụ lữu trữ & quản lý database hỗ trợ nhiều data model (multi-model) & có khả năng scale ở phạm vi toàn cầu, giúp bạn nhanh chóng xây dựng được một giải pháp database trên cloud với tính ổn định cao.
Azure Cosmos DB là gì?

Tiền thân của Azure Cosmos DB là Azure DocumentDB, cũng một dịch vụ về NoSQL database của Microsoft Azure tuy nhiên chỉ hỗ trợ data model cũng chính là tên của dịch vụ này luôn: document. Tuy nhiên vào sự kiện //Build 2017, Microsoft chính thức công bố Azure Cosmos DB, thay thế cho Azure DocumentDB tuy nhiên không chỉ dừng lại ở những gì mà dịch vụ tiền nhiệm của nó hỗ trợ mà còn cung cấp những khả năng mới & cải tiến. Cùng tìm hiểu các đặc điểm nổi bật của Cosmos DB bên dưới!
3 data model & 4 API được hỗ trợ
Hỗ trợ thêm 2 data model là Graph và Key-Value với API tương tác dữ liệu tương ứng là Germlin và Tables (bản chất là Azure Table Storage) API, nâng tổng số data model là 3 và API là 4 tính đến thời điểm viết bài viết này.
| API | Data Model |
| SQL | Document |
| MongoDB API | Document |
| Tables API | Key-Value |
| Gremlin | Graph |
Khả năng sao chép dữ liệu quy mô toàn cầu
Azure Cosmos DB có khả năng sao chép (replicate) toàn bộ dữ liệu trong database ra phạm vị toàn cầu với hơn 30 trung tâm lưu trữ dữ liệu (datacenter) của Microsoft Azure đặt tại hầu khắp các lục địa trên Thế giới.
Azure Cosmos DB cho phép replicate dữ liệu ra “không giới hạn” các khu vực có datacenter của Microsoft Azure ngoại trừ các khu vực bị giới hạn bởi rào cản địa lý hoặc luật pháp như Trung Quốc, Đức, …
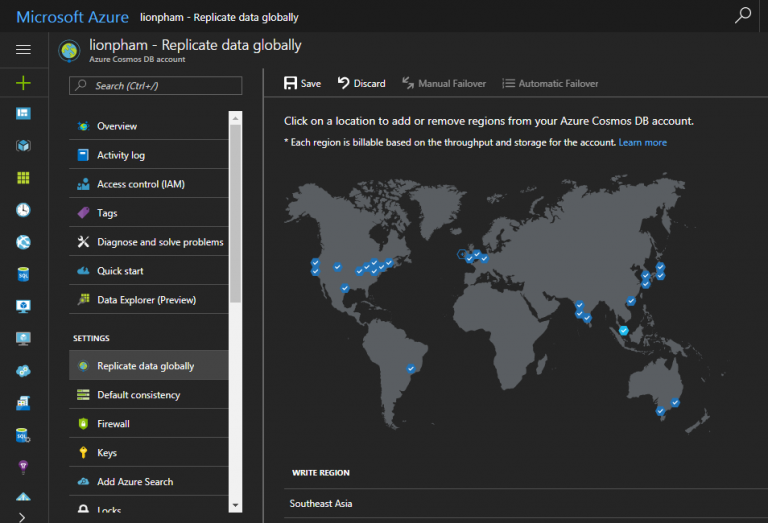
Mỗi khu vực có dữ liệu trong Cosmos DB bao gồm khu vực được chọn ở lúc khởi tạo ban đầu cũng như các khu vực được chọn để replicate dữ liệu sẽ được gọi là node trong bài viết này.
Việc cấu hình replicate dữ liệu ra các khu vực khác được Azure Cosmos DB thực hiện khá nhanh chóng với khả năng đảm bảo tính sẵn sàng của dữ liệu ở các node mới trong vòng 30 phút với dung lượng dữ liệu lên tới 100 TB.
Các khu vực được chọn để replicate dữ liệu sẽ đóng vai trò là các read node, tức các node chỉ đóng vai trò xử lý query lấy dữ liệu. Mặc định, khu vực được chọn đầu tiên trong quá trình khởi tạo Cosmos DB đóng vai trò là write node, tức node vừa xử lý query thêm & cập nhật dữ liệu và vừa hỗ trợ xử lý query lấy dữ liệu như read node. Tuy nhiên, bạn hoàn toàn có thể thay đổi khu vực của write node sau đó. Thông tin này mình sẽ chia sẻ ở nội dung bên dưới.
Lưu ý: Database lưu trên Cosmos DB chỉ có duy nhất 1 write node tuy nhiên có thể có nhiều read node.
Với khả năng replicate dữ liệu phạm vi toàn cầu như vậy, ứng dụng kết nối tới Azure Cosmos DB sẽ có độ trễ (latency) rất thấp với 99% các thao tác với dữ liệu được đảm bảo ở mức dưới 10 ms cho đọc và 15 ms cho ghi. Azure Cosmos DB sẽ điều hướng các request tới khu vực có dữ liệu sao chép gần nhất.
Ngoài ra, với việc hỗ trợ replicate dữ liệu ở phạm vi toàn cầu, Cosmos DB cung cấp giải pháp “chống sụp đổ” dựa trên cơ chế chuyển đổi dự phòng (failover) cho hệ thống database lưu trữ trên đây khi xảy ra các sự cố. Khi xảy ra sự cố ở phạm vi khu vực lớn như mất điện toàn bộ datacenter hoặc phạm vi toàn quốc gia hoặc đa quốc gia (một sự cố rất rất hiếm khi xảy ra), Cosmos DB có khả năng xử lý tự động theo thứ tự ưu tiện hoặc xử lý “bằng cơm”.
Cơ chế xử lý failover của Cosmos DB như thế nào?
Lấy một ví dụ về một hệ thống database lưu trên Cosmos DB có write node đặt tại West US và được cấu hình replicate dữ liệu ra 3 read node là North Europe, East Asia và Australia South với biểu đồ biểu diễn sau:

Cơ chế xử lý failover tự động
Đối với cơ chế xử lý failover tự động, Cosmos DB sẽ xử lý riêng cho từng loại node.
Xử lý cho read node

Trong trường hợp một read node nào đó bị gặp sự cố với ví dụ cụ thể ở đây là node đặt tại North Europe, ngay lập tức Azure sẽ ngắt kết nối nó với write node đặt tại West US và thiết lập trạng thái offline cho read node đó. Sau đó, bằng giao thức chuyên biệt có tên “regional discovery protocol” (RDP) trong bộ Cosmos DB SDK, Azure sẽ chuyển hướng tất cả các query lấy dữ liệu sang node kếtiếp được thiết lập trong danh sách PreferredLocations (chi tiết). Danh sách này có thể được thiết lập qua Cosmos DB SDK với cú pháp ví dụ bên dưới được viết bằng C# với mục đích thiết lập thêm 2 node đặt tại West US và North Europe vào danh sách PreferredLocations:
ConnectionPolicy connectionPolicy = new ConnectionPolicy
{
ConnectionMode = ConnectionMode.Direct,
ConnectionProtocol = Protocol.Tcp
};
connectionPolicy.PreferredLocations.Add(LocationNames.WestUS); // Thêm node ở West US vào danh sách
connectionPolicy.PreferredLocations.Add(LocationNames.NorthEurope); // Thêm node ở North Europe vào danh sách
DocumentClient client = new DocumentClient(
new Uri("ĐƯỜNG DẪN CỦA AZURE COSMOS DB"),
"KEY TRUY CẬP CỦA AZURE COSMOS DB",
connectionPolicy);
Trong trường hợp không có node nào được khai báo trong danh sách PreferredLocations, write node hiện tại sẽ được sử dụng làm read node. Quá trình failover này được thực hiện tự động bởi Azure và không cần bất cứ 1 hành động nào từ phía bạn cả.
Khi read node bị ảnh hưởng được khôi phục ví dụ là datacenter có điện trở lại, read node đó sẽ sync với write node hiện tại và sau đó khi sẵn sàng, nó sẽ được thiết lập lại về trạng thái online. Cosmos DB SDK cũng thông qua giao thức RDP, sẽ biết được khi có node mới online và sẽ kiểm tra xem node đó có trong danh sách PreferredLocations không. Trong trường hợp node mới nằm trong danh sách thì SDK sẽ kiểm tra hạng ưu tiên của node mới xem nó có cao hơn so với node hiện tại để thay thế làm read node không.
Xử lý cho write node
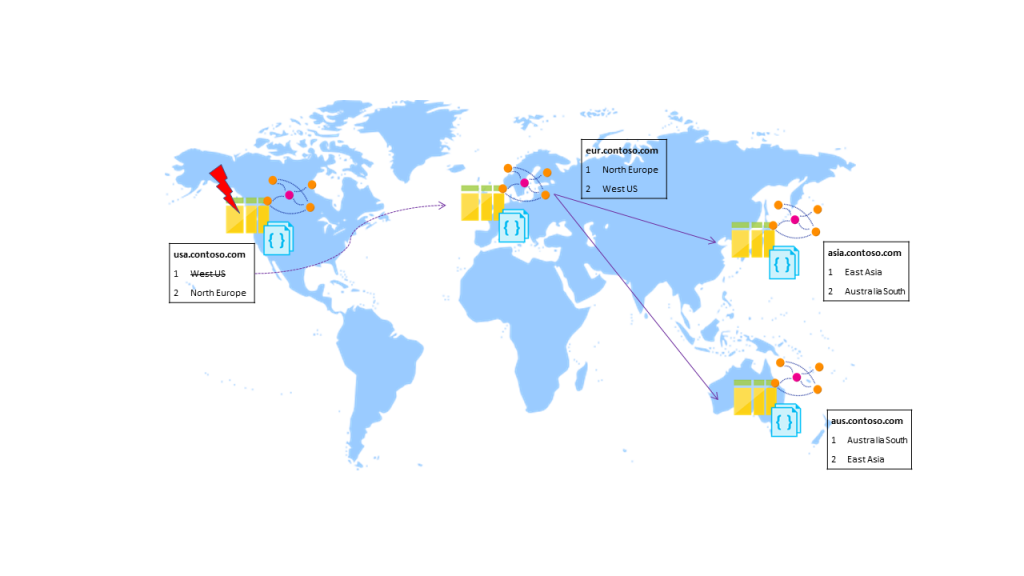
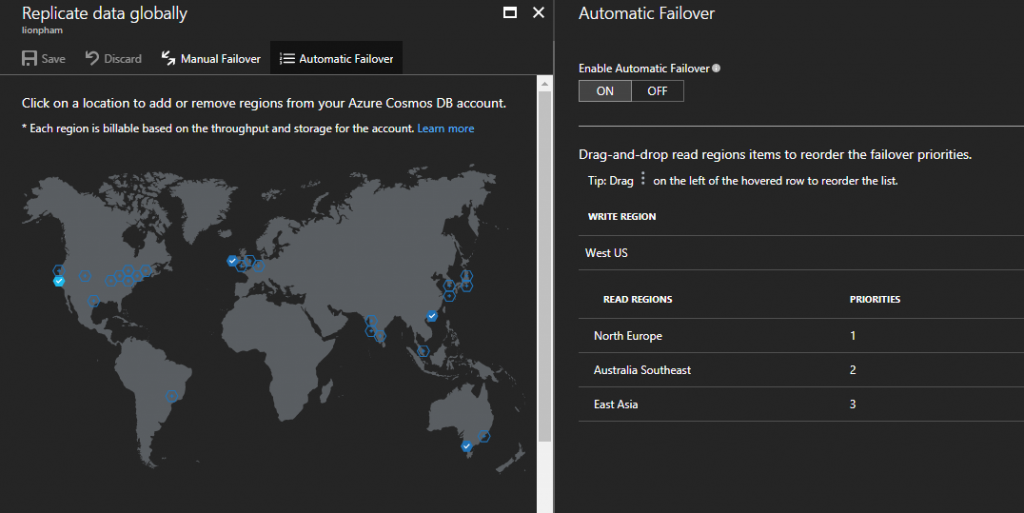
Tương tự với read node, write node đặt tại West US khi gặp sự cố sẽ được Azure thiết lập sang trạng thái offline. Sau đó, 1 trong các read node hiện tại sẽ được tự động lựa chọn để làm write node thay thế dựa vào thứ tự ưu tiên được bạn thiết lập trên portal của Cosmos DB (trong phần Replicate data globally\Automatic Failover) hoặc qua API.
Trong ví dụ ở đây thì node đặt tại North Europe sẽ được chọn làm write node thay thế theo thứ tự ưu tiên được thiết lập như hình bên dưới:
Khi sự cố được khắc phục, write node bị ảnh hưởng tức node đặt tại West US sẽ tiếp tục giữ ở trạng thái offline. Bạn cần phải thực hiện query tới node đó để tính toán các thay đổi được thực hiện trong khoảng thời gian gặp sự cố so với write node hiện tại tức node đặt tại North Europe. Sau đó, tùy theo yêu cầu của bạn, bạn thực hiện merge & giải quyết các conflict và cập nhật các thay đổi ngược trở lại write node hiện tại (đặt tại North Europe). Sau khi thực hiện merge & giải quyết các conflict hoàn tất, bạn có thể chuyển trạng thái của write node bị ảnh hưởng (West US) sang trạng thái online bằng một cách mà cá nhân mình thấy hơi bất tiện đó là gỡ node đó ra khỏi danh sách các node của Cosmos DB và sau đó thêm lại và thực hiện failover “bằng cơm” để cấu hình node đó (West US) là write node của database.
Cơ chế xử lý failover “bằng cơm”
Bằng cơm ở đây thực chất là được thực hiện bằng tay một cách thủ công :). Cơ chế xử lý failover bằng cơm này được xây dựng với mục đích chính là thay đổi write node hiện tại của database sang một node khác.
Bạn có thể thực hiện failover bằng cơm thông qua trang portal của Cosmos DB hoặc qua API.
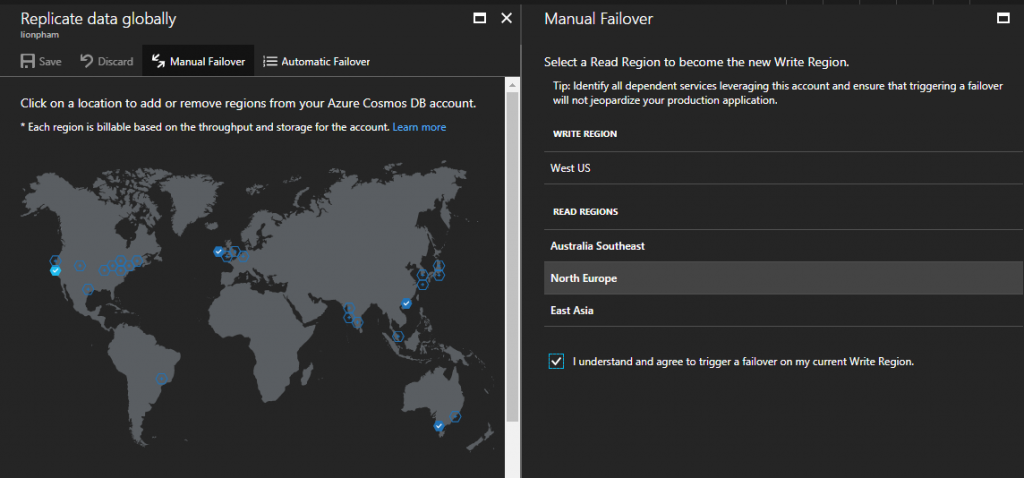
Tương tự cơ chế xử lý trong failover tự động, khi thay đổi write node mới thành công, Cosmos DB SDK sẽ tự động xử lý thay đổi này và đảm bảo query write (cập nhật, thêm mới) được trỏ tới write node mới mà không cần bạn phải cập nhật lại code hay làm bất cứ điều gì khác cả.
5 cấp độ đảm bảo tính nhất quán của dữ liệu
Một trong những bài toán cần phải giải quyết khi thực hiện replicate dữ liệu đó là đảm bảo tính nhất quán của dữ liệu.
Azure Cosmos DB được bổ sung thêm một cấp độ đảm bảo tính nhất quán dữ liệu mới là Consistent Prefix, nâng tổng số lượng cấp độ nhất quán của dữ liệu được hỗ trợ lên là 5 tính đến thời điểm viết bài viết này và hiện là dịch vụ NoSQL database trên cloud cung cấp nhiều cấp độ đảm bảo tính nhất quán của dữ liệu nhất (AWS DynamoDB hiện chỉ hỗ trợ Strong & Eventual hay Google Cloud Spanner chỉ hỗ trợ Strong).
 Với 5 cấp độ đảm bảo tính nhất quản của dữ liệu, bạn sẽ có nhiều lựa chọn hơn để lựa chọn một cấp độ phù hợp với bài toán của mình, cân bằng giữa 3 yếu tố trong định lý CAP (Consistency, Availability, Performance):
Với 5 cấp độ đảm bảo tính nhất quản của dữ liệu, bạn sẽ có nhiều lựa chọn hơn để lựa chọn một cấp độ phù hợp với bài toán của mình, cân bằng giữa 3 yếu tố trong định lý CAP (Consistency, Availability, Performance):
- Consistency – Mức độ nhất quán của dữ liệu
- Performance – Hiệu suất của việc truy suất dữ liệu
- Availability – Tính sẵn sàng của dữ liệu
Dưới đây là bảng so sánh “tradeoff” của 5 cấp độ đảm bảo tính nhất quán của dữ liệu theo định lý CAP mà Cosmos DB hỗ trợ để các bạn có thể tham khảo khi lựa chọn một cấp độ cho database của mình.
Thang đánh giá sẽ đi từ Kém > Trung Bình > Trung Bình+ > Cao.
| Cấp độ | Mức độ nhất quán | Hiệu suất | Tính sẵn sàng |
| Strong | Cao | Kém | Kém |
| Eventual | Kém | Cao | Cao |
| Consistent Prefix | Trung bình | Trung bình+ | Cao |
| Bounded Staleness | Trung bình+ | Trung bình | Kém |
| Session | Trung bình | Trung bình+ | Trung bình+ |
Khả năng mở rộng (scale out) linh hoạt
Một tính năng không còn xa lạ với hầu hết các dịch vụ của Microsoft Azure – scale-out, Azure Cosmos DB có khả năng mở rộng dung lượng lưu trữ cũng như khả năng chịu tải tại 1 thời điểm (throughput) một cách linh hoạt dựa trên đơn vị Request Unit (RU).
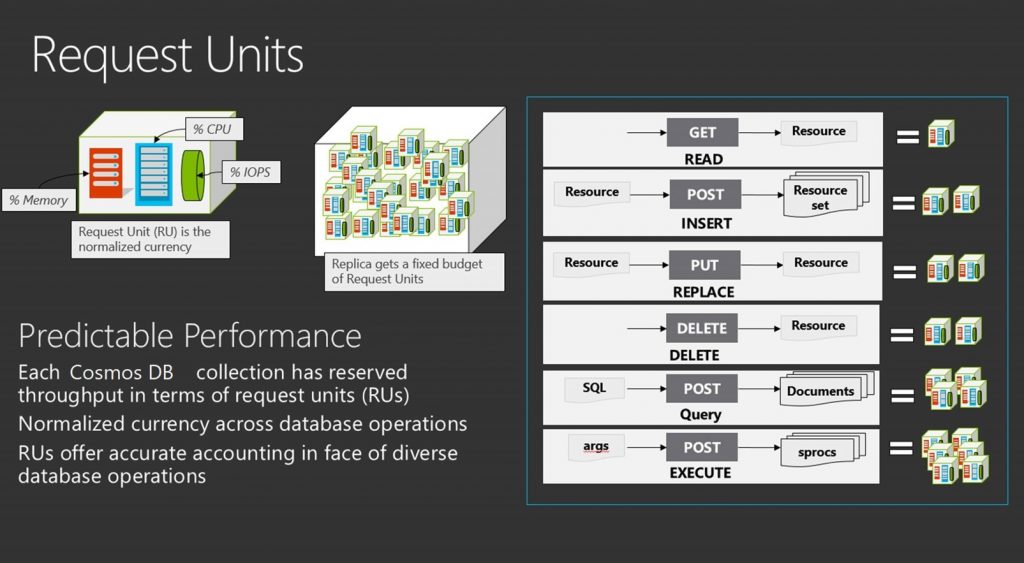
RU là đơn vị chuẩn hóa của Azure Cosmos DB nhằm đo số lượng tài nguyên như CPU, bộ nhớ RAM, số IOPS cần đến để xử lý các thao tác với database như thực hiện query đọc dữ liệu, ghi dữ liệu hay cập nhật dữ liệu trong database. Có thể coi RU là một đơn vị “tiền tệ” trong giao dịch của các hoạt động với database trên Cosmos DB.
Khi khởi tạo các container (collection trong document API, graph trong graph API và table trong table API) trong Cosmos DB, bạn cần phải khai báo trước 1 lượng throughput ban đầu cụ thể cho container đó như là một lượng RU dự trữ. Bạn có thể tham khảo công cụ ước lượng số RU cần theo một số tiêu chí đầu vào như số item, số lượng các thao tác CRUD trong 1 giây của bài toán của bạn tại đây. Ngoài RU, công cụ này cũng cho biết được số lượng dung lượng cần để lưu trữ là bao nhiêu.
Azure Cosmos DB cho phép bạn xây dựng cấu hình thoughput của container theo block 100 RU/s (100 RU trong 1 giây), đây là con số tối thiểu cho mỗi lần bạn tăng hoặc giảm cấu hình thoughput của Cosmos DB. Một điểm hay của Cosmos DB đó là cho phép bạn kết hợp cấu hình thoughput giữa 2 đơn vị RU/s và RU/m (RU trong 1 phút). Với mỗi 100 RU/s được thêm vào throughput, bạn sẽ nhận được 1000 RU/m, tức 10 lần số lượng RU/s. Việc kết hợp 2 đơn vị này cho phép tiết kiệm chi phí lên tới 75% so với chỉ sử dụng cấu hình RU/s, cùng xem một ví dụ sau:
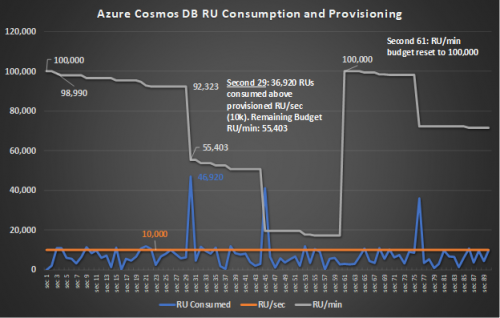
Đây là một biểu đồ biểu diễn số lượng RU thiêu thụ của 1 Azure Cosmos DB với cấu hình throughput ban đầu có hạn ngạch (quota) là 10,000 RU/s và tùy chọn sử dụng song song với RU/m có quota là 100,000 RU/m.
- Ở trong khoảng từ giây đầu tiên đến giây thứ 3, tổng số lượng RU tiêu thu ở mức dưới 10,000 RU, do vậy số RU ở 2 giây đầu này sẽ rút từ “kho” RU/s.
- Ở giây thứ 3, số lượng RU tăng vọt với 11,010 RU được thực hiện, con số này vượt quá quota 10,000 của RU/s tổng cộng 1010 RU. Tuy nhiên do có sử dụng song song RU/m, 1010 RU này được rút từ “kho” RU/m và tại thời điểm đó, quota của kho RU/m là 98,990 RU cho 57 giây còn lại cho 1 block thời gian 1 phút của RU/m.
- Trong khoảng thời gian từ giây thứ 3 tới giây thứ 29, trong khoảng thời gian này có một vài thời điểm có biến động số lượng RU thực hiện trong 1 giây vượt quá 10,000 và được rút từ kho RU/m, làm giảm quota của RU/m xuống còn 92,323.
- Tại giây thứ 29, một lượng lớn RU được thực hiện, gấp hơn 4 lần quota của RU/s, với 46,920 RU được thực hiện, kéo quota của RU/m xuống 55,403.
- Tại giây thứ 61, quota của RU/m được reset về 100,000.
Qua ví dụ trên bạn có thể thấy được rằng RU/m đã giúp Azure Cosmos DB xử lý được những thời điểm có lượng RU vượt quá quota của thiết lập RU/s ban đầu. Câu hỏi đặt ra tại sao không thiết lập quote của RU/s cao lên, 47,000 RU chẳng hạn (số RU tối đa trong 1 giây ở ví dụ trên)? Bạn hoàn toàn có thể thiết lập như vậy tuy nhiên có 2 vấn đề:
- Thiết lập dự trữ 1 lượng lớn RU/s trong khi số lượng thiêu thụ trung bình thực tế lại nhỏ hơn nhiều số dự trữ và số lượng RU thực hiện tại 1 giây đạt hoặc gần đạt số quota của RU/s xảy ra không nhiều.
- Thiết lập quota của RU/s cao lên đồng nghĩa với tổng chỉ phí cho Azure Cosmos DB tăng lên. Tính đến thời điểm viết bài viết này, chi phí cho mỗi block 100 RU/s là $0.008/giờ và cho mỗi block 1000 RU/m là $0.002688/giờ (tham khảo giá chính xác tại đây), cùng làm 1 phép tính đơn giản:
Không sử dụng RU/m, cấu hình với throughput tối đa 47,000 RU/s:
| Số lượng RU/s | Giá mỗi block 100 RU/s | Tổng chi phí cho 1 tháng sử dụng Azure Cosmos DB tương đương 744 giờ |
| 47,000 | $0.008 | $279.74 |
Sử dụng RU/m, cấu hình với throughput tối đa 10,000 RU/s với 100,000 RU/m:
| Số lượng RU/s | Giá mỗi block 100 RU/s | Số lượng RU/m | Giá mỗi block 1000 RU/m (làm tròn) | Tổng chi phí cho 1 tháng sử dụng Azure Cosmos DB tương đương 744 giờ |
| 10,000 | $0.008 | 10,000 | $0.003 | $79.52 |
Có thể thấy chi phí sử dụng RU/m rẻ hơn rất nhiều (khoảng 73%) so với không sử dụng tuy nhiên vẫn giải quyết được bài toán xử lý cho 47,000 RU trong 1 giây ở 1 số thời điểm “peek”.
Điều gì xảy ra nếu vượt quá throughput?
Trong trường hợp số lượng quota RU/s và RU/m bị rút hết, Cosmos DB sẽ đóng request lại và trả về mã lỗi 429 - RequestRateTooLargeException kèm theo số millisecond là thời gian cần phải chờ để có thể thử lại trong header x-ms-retry-after-ms.
Một header ví dụ của trường hợp vượt quá throughput với thời gian chờ là 58 ms:
HTTP Status 429 Status Line: RequestRateTooLarge x-ms-retry-after-ms:58
Azure Cosmos DB Emulator
Để bắt đầu với Azure Cosmos DB bạn có thể tạo mới dịch vụ Cosmos DB trên Azure portal. Tuy nhiên, bạn cũng có thể trải nghiệm & phát triển ứng dụng với Azure Cosmos DB ngay trên máy local của mình thông qua bộ Azure Cosmos DB Emulator.
Azure Cosmos DB Emulator là bộ giả lập môi trường Azure Cosmos DB ngay trong máy local. Với Azure Cosmos DB Emulator thì bạn có thể phát triển ứng dụng với Azure Cosmos DB mà không cần có subscription của Microsoft Azure cũng như không phải lo lắng vấn đề thu phí sử dụng trong quá trình phát triển.
Lưu ý: Máy local của bạn cần phải có tối thiểu 2 GB RAM và 10 GB ổ đĩa trống để có thể sử dụng được Azure Cosmos DB Emulator.
Tìm hiểu thêm về Azure Cosmos DB Emulator tại đây.
Kết luận
Nằm trong bộ dịch vụ NoSQL PaaS của Microsoft Azure, Cosmos DB mang tới cho các nhà phát triển một giải pháp lưu trữ NoSQL database hỗ trợ nhiều data model cùng khả năng phân phối dữ liệu ở phạm vi toàn cầu.
Azure Cosmos DB phù hợp cho các bài toán có ứng dụng phân phối ở phạm vi toàn cầu cần đảm bảo độ trễ thấp khi truy suất dữ liệu, hay các bài toán về IoT với các yêu cầu về một database có khả năng chịu tải lớn phục vụ cho real-time analytics, hỗ trợ scale linh hoạt cũng như hỗ trợ thực hiện các adhoc query với hiệu suất cao.
Trên là những giới thiệu nhanh qua về Cosmos DB và một số đặc điểm thú vị của dịch vụ này. Thực ra còn một số điểm thú vị khác nữa tuy nhiên mình sẽ để dành chia sẻ ở một bài viết khác :). Hy vọng bài viết này một phần nào mang đến cho bạn một cái nhìn cũng khá chi tiết về dịch vụ Azure Cosmos DB mới này!
Update 11/9/2017: Microsoft vừa cho ra mắt chương trình Try Azure Cosmos DB for free, mang đến cho lập trình viên cơ hội trải nghiệm các tính năng của Azure Cosmos DB hoàn toàn miễn phí trong 24 tiếng. Sau 24 tiếng, bạn có thể đăng ký để gia hạn thêm thời gian để tiếp tục sử dụng. Thông tin chi tiết về chương trình trên bạn có thể tham khảo thêm tại đây.
Rất chi tiết! Hy vọng sẽ sớm được đón đọc bài viết chia sẻ “một số điểm thú vị khác” về Cosmos DB của bạn.
Cảm ơn Anh rất nhiều về những bài viết này. Chủ đề này rất ít thấy có ở các bloger Việt.